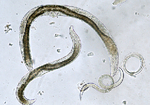
前々回に、ヒトゲノム・データベースサービスのグーグル・ゲノミクスを紹介した。グーグル・ゲノミクスのデータは、一般対象ではなく研究者向けのものだ。しかし、個人を特定できる年齢、性別、住所、電話番号、社会保険データ、病歴、生体データ、家系データなどの情報が多いほど、研究者には有用だが、個人を特定する精度が高まるのは明白だ。
アーリック博士が指摘するように、個人のプライバシーを保護するためには、ガイドラインの標準化やコンプライアンスの強化が図られるべきだ。それは、ヒトゲノム・データベースサービスだけでなく、DTC遺伝子検査サービスなど、公的・私的を問わず遺伝子ビジネスに関わるすべての機関や企業のもつべき公的な倫理であり、果たすべき社会的な責務でもある。
今回は、遺伝子データベースから、どのようにして個人の素性が特定され、暴かれるリスクがあるかをレポートした。次回は、危惧される遺伝子情報の差別や個人のプライバシー問題を深く掘り下げてみよう。
佐藤博(さとう・ひろし)
大阪生まれ・育ちのジャーナリスト、プランナー、コピーライター、ルポライター、コラムニスト、翻訳者。同志社大学法学部法律学科卒業後、広告エージェンシー、広告企画プロダクションに勤務。1983年にダジュール・コーポレーションを設立。マーケティング・広告・出版・編集・広報に軸足をおき、起業家、経営者、各界の著名人、市井の市民をインタビューしながら、全国で取材活動中。医療従事者、セラピストなどの取材、エビデンスに基づいたデータ・学術論文の調査・研究・翻訳にも積極的に携わっている。
連載「遺伝子検査は本当に未来を幸福にするのか?」バックナンバー